Sunday 11 November 2012
Wappalyzer - Browser Extension To Identify Web Servers
Wappalyzer is a very useful browser extension that reveals the web technologies and server softwares used behind to empower any webpage. This extension identifies different CMS, e-commerce portals, blogging platforms, web servers, frameworks, analytic tools, etc.
This very useful browser extension is available for Mozilla Firefox and Google Chrome. It is quite useful in server fingerprinting and identification steps. Wappalyzer tracks and detects several hundred applications under several categories.
Wappalyzer for Mozilla Firefox
Wappalyzer for Google Chrome
Wappalyzer @ GitHub
Once you install the addon and reload the browser, you will see the icons for identified applications on the right side of address bar (near to the bookmark & reload icon) in Mozilla Firefox. You can click in that area for more details.
One particular setting you would like to disable is the tracking and gathering of anonymous data which is *said* to be used for research purposes. You can turn off the tracking by going to the addon's preference page. Screenshot below shows the preference page in Mozilla Firefox.
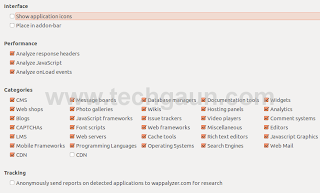
Read more...
This very useful browser extension is available for Mozilla Firefox and Google Chrome. It is quite useful in server fingerprinting and identification steps. Wappalyzer tracks and detects several hundred applications under several categories.
Wappalyzer for Mozilla Firefox
Wappalyzer for Google Chrome
Wappalyzer @ GitHub
Once you install the addon and reload the browser, you will see the icons for identified applications on the right side of address bar (near to the bookmark & reload icon) in Mozilla Firefox. You can click in that area for more details.
One particular setting you would like to disable is the tracking and gathering of anonymous data which is *said* to be used for research purposes. You can turn off the tracking by going to the addon's preference page. Screenshot below shows the preference page in Mozilla Firefox.

Read more...
Bookmark this post: | 
|
Wednesday 7 November 2012
Steam Beta For Linux Released, Use Steam Beta Right Now
Finally the steam beta was released today and is ready for beta testing by the selected 1000 beta testers who were chosen through the Steam For Linux Beta Survey. This post also provides the steps for using steam beta for other users who were not selected.
Don't worry if you were not lucky enough to get a Beta account in Steam for linux survey. Some of the Reddit users have found a way around this and non-beta account holder can use steam for linux beta.
The post from Valve Software writes:
The Valve Linux team is proud to announce the launch of a limited access beta for its new Steam for Linux client.
The Steam for Linux Beta client supports the free-to-play game Team Fortress 2. Approximately two dozen additional Steam titles are now also available for play on Ubuntu. Additionally, the Steam for Linux Beta client includes Big Picture, the mode of Steam designed for use with a TV and controller, also currently in beta.
Below are the steps you should follow in order to use steam beta in your linux. First, type the following commands in the terminal:
The steam installer will then download and update the data for steam client. Once the update is finished, launch the steam from Unity dash and then login to your steam account (or create one). Close your steam client and then type the followin in terminal or just update your shortcut with following shortcut:
Enjoy steam in your linux :)
Read more...
Don't worry if you were not lucky enough to get a Beta account in Steam for linux survey. Some of the Reddit users have found a way around this and non-beta account holder can use steam for linux beta.
The post from Valve Software writes:
The Valve Linux team is proud to announce the launch of a limited access beta for its new Steam for Linux client.
The Steam for Linux Beta client supports the free-to-play game Team Fortress 2. Approximately two dozen additional Steam titles are now also available for play on Ubuntu. Additionally, the Steam for Linux Beta client includes Big Picture, the mode of Steam designed for use with a TV and controller, also currently in beta.
Below are the steps you should follow in order to use steam beta in your linux. First, type the following commands in the terminal:
samar@samar-Techgaun:~$ sudo apt-get install libopenal1
samar@samar-Techgaun:~$ wget http://media.steampowered.com/client/installer/steam.deb && sudo dpkg -i steam.deb
samar@samar-Techgaun:~$ wget http://media.steampowered.com/client/installer/steam.deb && sudo dpkg -i steam.deb
The steam installer will then download and update the data for steam client. Once the update is finished, launch the steam from Unity dash and then login to your steam account (or create one). Close your steam client and then type the followin in terminal or just update your shortcut with following shortcut:
steam steam://open/games
Enjoy steam in your linux :)
Read more...
Bookmark this post: |
|
Monday 5 November 2012
ImageShack and Symantec Hacked And Dumped
2012 has been a year of leaks and hacks and continues to be so. Hackers hacked into ImageShack and Symantec servers and have leaked several critical information regarding the servers and employees.
Hackers have disclosed in an e-zine that the security practices of these major companies have been a joke: In case of ImageShack, all MySQL instances as root, really old (2008) kernels, hardcode database passwords, enable register_globals, etc.
The e-zine says:
ImageShack has been completely owned, from the ground up. We have had root and physical control of every server and router they own.
Likewise, they have dumped the database of Symantec, one of the leading AV companies which includes the critical information of the researchers at Symantec.
Links
Pastebin
AnonPaste
Read more...
Hackers have disclosed in an e-zine that the security practices of these major companies have been a joke: In case of ImageShack, all MySQL instances as root, really old (2008) kernels, hardcode database passwords, enable register_globals, etc.
The e-zine says:
ImageShack has been completely owned, from the ground up. We have had root and physical control of every server and router they own.
Likewise, they have dumped the database of Symantec, one of the leading AV companies which includes the critical information of the researchers at Symantec.
Links
Pastebin
AnonPaste
Read more...
Bookmark this post: |
|
Saturday 3 November 2012
Bypass Slot Reservation In Counter Strike 1.6
So you are crazy about CS but your local servers are always packed and can not enter the servers due to slot reservations for admins? Don't worry, this guide will provide an insight and step by step details on how to bypass slot reservation in Amx Mod X powered servers.
I checked the source code of slot reservation plugin (adminslots.sma) from AMXMODX source and found out that the admin slot plugin was executing a brute-force vulnerable randomized command at the client end. See the line of code below:
The bruteforce space is quite small, 4 uppercase characters from A-Z i.e. 26 * 26 * 26 * 26 combination is the maximum amount of search required to find the random part of the command. Hence, the command executed at client end is amxresXXXX where {X: X belongs to [A-Z]}. If there are still slots available for normal players or if the connecting user has slot reservation privilege, he will be able to connect to the server otherwise the server will kick the user. We are not going to bruteforce but we are going to use a memory viewer and editor software that is capable of reading the contents in the memory (RAM).
Basically, we hook into the Counter Strike client process from one of the freely available memory editors. We then connect to the server and get dropped due to the slot reservation message. In the meantime, the server sends the partial-random command.. FYI, these memory viewers make use of kernel APIs such as ReadProcessMemory() to read the memory layout of any process. We search for the initial part of the string which is amxres.
Once we find the unique string sent by server to our client, we use the alias command with amxresXXXX as our alias. For your info, alias provides a mechanism to group different commands to achieve something more useful.
The syntax of alias is: alias "alias_name" "cmd1; cmd2; ...; cmdn" And here we've just created an alias "amxresXXXX" which does nothing since the commands list is missing there.
The tool I've used here is ArtMoney available for download at http://www.artmoney.ru/e_download_se.htm In case, the site goes down, you can get it from here: http://www.4shared.com/file/wm7V4pgv/artmoney740eng.html
Several similar tools exist & are available for free. Some of them are CheatEngine (http://cheatengine.org/downloads.php) and Poke (http://codefromthe70s.org/poke.aspx)
Check the video below for more information:
Read more...
format(g_cmdLoopback, 15, "amxres%c%c%c%c", random_num('A', 'Z'), random_num('A', 'Z'), random_num('A', 'Z'), random_num('A', 'Z'))
The bruteforce space is quite small, 4 uppercase characters from A-Z i.e. 26 * 26 * 26 * 26 combination is the maximum amount of search required to find the random part of the command. Hence, the command executed at client end is amxresXXXX where {X: X belongs to [A-Z]}. If there are still slots available for normal players or if the connecting user has slot reservation privilege, he will be able to connect to the server otherwise the server will kick the user. We are not going to bruteforce but we are going to use a memory viewer and editor software that is capable of reading the contents in the memory (RAM).
Basically, we hook into the Counter Strike client process from one of the freely available memory editors. We then connect to the server and get dropped due to the slot reservation message. In the meantime, the server sends the partial-random command.. FYI, these memory viewers make use of kernel APIs such as ReadProcessMemory() to read the memory layout of any process. We search for the initial part of the string which is amxres.
Once we find the unique string sent by server to our client, we use the alias command with amxresXXXX as our alias. For your info, alias provides a mechanism to group different commands to achieve something more useful.
The syntax of alias is: alias "alias_name" "cmd1; cmd2; ...; cmdn" And here we've just created an alias "amxresXXXX" which does nothing since the commands list is missing there.
The tool I've used here is ArtMoney available for download at http://www.artmoney.ru/e_download_se.htm In case, the site goes down, you can get it from here: http://www.4shared.com/file/wm7V4pgv/artmoney740eng.html
Several similar tools exist & are available for free. Some of them are CheatEngine (http://cheatengine.org/downloads.php) and Poke (http://codefromthe70s.org/poke.aspx)
Check the video below for more information:
Read more...
Bookmark this post: |
|
Make Your Linux Read Papers For You
Fed up of reading text files and PDF papers? Is you eye power degrading day by day and can't hold even few minutes on screen? Don't worry, you can easily make your linux system speak and read all those papers for you.
There are several text to speech tools available for linux but in this post, I will be using festival, a Text-to-speech (TTS) tool written in C++. Also, Ubuntu and its derivation are most likely to include by default espeak, a multi-lingual software speech synthesizer.
For ubuntu and debian based system, type the following to install festival:
Moreover, you can also install a pidgin plugin that uses festival:
For now, you just need to install festival. Once you have installed festival, you can make it read text files for you. If you go through the online manual of festival, it says:
"Festival works in two fundamental modes, command mode and text-to-speech mode (tts-mode). In command mode, information (in files or through standard input) is treated as commands and is interpreted by a Scheme interpreter. In tts-mode, information (in files or through standard input) is treated as text to be rendered as speech. The default mode is command mode, though this may change in later versions."
To read a text file, you can use the command below:
The festival will start in text-to-speech (tts) mode and will read your text files for you. But now, we want to read PDF files and if you try to read PDF files directly (festival --tts paper.pdf), festival is most likely to speak the cryptic terms since it actually reads the content of PDF including its header (You know PDF is different than simple text file). So we will use a pdftotext command to convert our pdf file and then pipe the output to the festival so that festival reads the PDF files for us. You can use the syntax as below to read PDF files.
If you want to skip all those table of contents and prefaces or if you are in the middle of PDF, you can use the switches of pdftotext to change the starting and ending pages. For example, if I wish to read page 10 - 14 of a PDF, I would do:
Enjoy learning. I hope this post helps you ;)
Read more...
There are several text to speech tools available for linux but in this post, I will be using festival, a Text-to-speech (TTS) tool written in C++. Also, Ubuntu and its derivation are most likely to include by default espeak, a multi-lingual software speech synthesizer.
For ubuntu and debian based system, type the following to install festival:
samar@samar-Techgaun:~$ sudo apt-get install festival
Moreover, you can also install a pidgin plugin that uses festival:
samar@samar-Techgaun:~$ sudo apt-get install pidgin-festival
For now, you just need to install festival. Once you have installed festival, you can make it read text files for you. If you go through the online manual of festival, it says:
"Festival works in two fundamental modes, command mode and text-to-speech mode (tts-mode). In command mode, information (in files or through standard input) is treated as commands and is interpreted by a Scheme interpreter. In tts-mode, information (in files or through standard input) is treated as text to be rendered as speech. The default mode is command mode, though this may change in later versions."
To read a text file, you can use the command below:
samar@samar-Techgaun:~$ festival --tts mypaper.txt
The festival will start in text-to-speech (tts) mode and will read your text files for you. But now, we want to read PDF files and if you try to read PDF files directly (festival --tts paper.pdf), festival is most likely to speak the cryptic terms since it actually reads the content of PDF including its header (You know PDF is different than simple text file). So we will use a pdftotext command to convert our pdf file and then pipe the output to the festival so that festival reads the PDF files for us. You can use the syntax as below to read PDF files.
samar@samar-Techgaun:~$ pdftotext paper.pdf - | festival --tts
If you want to skip all those table of contents and prefaces or if you are in the middle of PDF, you can use the switches of pdftotext to change the starting and ending pages. For example, if I wish to read page 10 - 14 of a PDF, I would do:
samar@samar-Techgaun:~$ pdftotext -f 10 -l 14 paper.pdf - | festival --tts
Enjoy learning. I hope this post helps you ;)
Read more...
Bookmark this post: |
|
Wednesday 31 October 2012
CodeWeavers Announces Free CrossOver Giveaway
CodeWeavers, the developer of CrossOver has decided to run a 24-hour free giveaway for their famous wine-based product, CrossOver.
CrossOver allows you to install many popular Windows applications and PC games on your Linux computer. It's easy, affordable, and best of all, there's no Windows license required. Your Windows applications and games integrate seamlessly on your computer; just click and run. CrossOver is capable of running a wide range of Windows software and games.
On Wednesday, Oct. 31, 2012, beginning at 00:00 Central Time (-5 GMT), anyone visiting CodeWeavers’ Flock The Vote promotional web site (flock.codeweavers.com) will be able to download a free, fully functional copy of either CrossOver Mac or CrossOver Linux. Each copy comes complete with 12 months of support and product upgrades. Upon registering your name and e-mail address along with your version (CrossOver Mac or CrossOver Linux), you will get an e-mail with the instructions for download. The offer will continue for 24 hours, from 00:00 to 23:59, Oct. 31, 2012. Flock The Vote is an initiative to get more Americans to vote in the upcoming 2012 Presidential elections.
Update: direct download links:
32 bit Debian/Ubuntu
64 bit Debian/Ubuntu
32/64 bit Red Hat (Fedora, SUSE, Mandriva)
Installer for all other linux distros
Mac and Others
Sandy survivors, you can still get the offer from HERE.
Read more...
CrossOver allows you to install many popular Windows applications and PC games on your Linux computer. It's easy, affordable, and best of all, there's no Windows license required. Your Windows applications and games integrate seamlessly on your computer; just click and run. CrossOver is capable of running a wide range of Windows software and games.
On Wednesday, Oct. 31, 2012, beginning at 00:00 Central Time (-5 GMT), anyone visiting CodeWeavers’ Flock The Vote promotional web site (flock.codeweavers.com) will be able to download a free, fully functional copy of either CrossOver Mac or CrossOver Linux. Each copy comes complete with 12 months of support and product upgrades. Upon registering your name and e-mail address along with your version (CrossOver Mac or CrossOver Linux), you will get an e-mail with the instructions for download. The offer will continue for 24 hours, from 00:00 to 23:59, Oct. 31, 2012. Flock The Vote is an initiative to get more Americans to vote in the upcoming 2012 Presidential elections.
Get Free Copy Of CrossOver
Update: direct download links:
32 bit Debian/Ubuntu
64 bit Debian/Ubuntu
32/64 bit Red Hat (Fedora, SUSE, Mandriva)
Installer for all other linux distros
Mac and Others
Sandy survivors, you can still get the offer from HERE.
Read more...
Bookmark this post: |
|
Tuesday 30 October 2012
Download MakeUseOf.com Guides - Google Dork
Well makeuseof.com guides are good read for the average computer users and sometimes the guide from them can be quite useful for startup in particular topic. But, I hate the ways we need to follow to download so here's a simple google dork to find PDFs from makeuseof.com
MakeUseOf.Com provides three methods to download the guides: social media sharing, 99 cent payment, and subscription to their newsletter. I hate when sites impose such things and here is how you can get those PDFs directly.
Go to google and type the following in search box:
or, CLICK HERE!!!
Enjoy free MakeUseOf.Com guides ;)
Read more...
MakeUseOf.Com provides three methods to download the guides: social media sharing, 99 cent payment, and subscription to their newsletter. I hate when sites impose such things and here is how you can get those PDFs directly.
Go to google and type the following in search box:
site:amazonaws.com inurl:makeuseof.com
or, CLICK HERE!!!
Enjoy free MakeUseOf.Com guides ;)
Read more...
Bookmark this post: |
|
Download Advanced NLP Documents
In this post, you will be able to download advanced natural language processing slides and assignments that were used as the study material during the course conducted in Kathmandu University on 27th August - 21st September, 2012.
The course program comprised of two graduate level courses, which are itself divided up into two modules. The two courses are: 1) Advanced Linguistic Resources; 2) Advanced Applications for Natural Language Processing. The official website for the course was up for a while but seems to be down now so I decided to upload these documents for you guys.
Module A: Grammars and Treebanks for Syntactic Processing
(Stefanie Dipper, Univ. Bochum and Heike Zinsmeister, Univ. Stuttgart)
Syntactic preprocessing is becoming more and more important for NLP applications, such as Anaphora Resolution or Phrase-Based Statistical Machine Translation (see Course 2). This course aims at getting students acquainted with relevant state-of-the-art resources for syntactic processing, teaching them how to use and evaluate them, and enabling them to create such resources on their own. Course topics include: symbolic and statistical models for syntactic processing for NLP applications; Resources for syntactic analysis — grammars and their use in parsers; annotated corpora — constituency- and dependency-based treebanks; evaluation measures for inter-annotator agreement and system evaluation. The course will be a combination of lectures and hands-on practice in applying and developing tools for syntactic processing. The lectures are complemented by extensive hands-on exercises. Students will be encouraged to practice and create their own resources.
Module B: Word and Verb Nets for Semantic Processing
(Miriam Butt, Univ. Konstanz and Annette Hautli, Univ. Konstanz)
The course will provide an introduction to existing lexical resources for English such as WordNet, VerbNet and PropBank and why they have proven to be useful for NLE. A WordNet, VerbNet and PropBank for Hindi are currently being created as part of various projects in India, the USA and Germany and the course will use the preliminary versions of the Hindi resources to introduce students to the special structures found in South Asian languages and to discuss where different design decisions need to be made. The course will also show students why it is important to understand established linguistic categories with regard to lexical structure and lexical semantics and how that can help guide the classification and encoding of lexical information in lexical resources in a manner that will be useful to NLE.
Module A: Statistical Machine Translation
(Alex Fraser, Univ. Stuttgart)
The goal of the course is to have students acquire in depth knowledge of statistical machine translation methods and be familiar with the relevant iterature and an open source statistical machine translation system. The course will cover: Basic statistical modeling for machine translation; Automatic and manual evaluation of machine translation output; Bitext alignment of parallel sentence pairs; Basic phrase-based statistical machine translation models and decoding; Log-linear models and minimum error rate training; Discriminative word alignment; morphological and syntactic modeling.
Module B: Automatic Speech Recognition
(Sarmad Hussain, Univ. of Engineering and Technology)
The course will start by covering articulatory and acoustic phonetics, followed by some basis understanding of speech processing needed to separate the phonetic content from a speech signal. The course will then develop an understanding of the Baysian model for speech recognition and its implementation using Hidden Markov Models, covering both training and decoding algorithms. Finally the course will focus on practical aspects of designing, developing and labeling a speech corpus and using tool-kits to develop speech recognition models. The course will have two labs, first on acoustic phonetics and second on developing a prototype speech recognition system with limited vocabulary.
Update
Thanks to Rohit Man Amatya, one of the participants of Summer School. He has written installation scripts for debian based systems and provided a list of what needs to be installed for working on the whole course. Plus the solutions for programming assignments.
Read more...
The course program comprised of two graduate level courses, which are itself divided up into two modules. The two courses are: 1) Advanced Linguistic Resources; 2) Advanced Applications for Natural Language Processing. The official website for the course was up for a while but seems to be down now so I decided to upload these documents for you guys.
Course 1: Advanced Resources for Natural Language Processing
Module A: Grammars and Treebanks for Syntactic Processing
(Stefanie Dipper, Univ. Bochum and Heike Zinsmeister, Univ. Stuttgart)
Syntactic preprocessing is becoming more and more important for NLP applications, such as Anaphora Resolution or Phrase-Based Statistical Machine Translation (see Course 2). This course aims at getting students acquainted with relevant state-of-the-art resources for syntactic processing, teaching them how to use and evaluate them, and enabling them to create such resources on their own. Course topics include: symbolic and statistical models for syntactic processing for NLP applications; Resources for syntactic analysis — grammars and their use in parsers; annotated corpora — constituency- and dependency-based treebanks; evaluation measures for inter-annotator agreement and system evaluation. The course will be a combination of lectures and hands-on practice in applying and developing tools for syntactic processing. The lectures are complemented by extensive hands-on exercises. Students will be encouraged to practice and create their own resources.
Module B: Word and Verb Nets for Semantic Processing
(Miriam Butt, Univ. Konstanz and Annette Hautli, Univ. Konstanz)
The course will provide an introduction to existing lexical resources for English such as WordNet, VerbNet and PropBank and why they have proven to be useful for NLE. A WordNet, VerbNet and PropBank for Hindi are currently being created as part of various projects in India, the USA and Germany and the course will use the preliminary versions of the Hindi resources to introduce students to the special structures found in South Asian languages and to discuss where different design decisions need to be made. The course will also show students why it is important to understand established linguistic categories with regard to lexical structure and lexical semantics and how that can help guide the classification and encoding of lexical information in lexical resources in a manner that will be useful to NLE.
Course 2: Advanced Applications for Natural Language Processing
Module A: Statistical Machine Translation
(Alex Fraser, Univ. Stuttgart)
The goal of the course is to have students acquire in depth knowledge of statistical machine translation methods and be familiar with the relevant iterature and an open source statistical machine translation system. The course will cover: Basic statistical modeling for machine translation; Automatic and manual evaluation of machine translation output; Bitext alignment of parallel sentence pairs; Basic phrase-based statistical machine translation models and decoding; Log-linear models and minimum error rate training; Discriminative word alignment; morphological and syntactic modeling.
Module B: Automatic Speech Recognition
(Sarmad Hussain, Univ. of Engineering and Technology)
The course will start by covering articulatory and acoustic phonetics, followed by some basis understanding of speech processing needed to separate the phonetic content from a speech signal. The course will then develop an understanding of the Baysian model for speech recognition and its implementation using Hidden Markov Models, covering both training and decoding algorithms. Finally the course will focus on practical aspects of designing, developing and labeling a speech corpus and using tool-kits to develop speech recognition models. The course will have two labs, first on acoustic phonetics and second on developing a prototype speech recognition system with limited vocabulary.
Download Course Material
Update
Thanks to Rohit Man Amatya, one of the participants of Summer School. He has written installation scripts for debian based systems and provided a list of what needs to be installed for working on the whole course. Plus the solutions for programming assignments.
Summer School @ GitHub
Read more...
Bookmark this post: |
|
Subscribe to:
Posts (Atom)